Как работает React Reconciliation
- Published on
- Authors
- Name
- Vasiliy Kramarenko
- @kramvas07

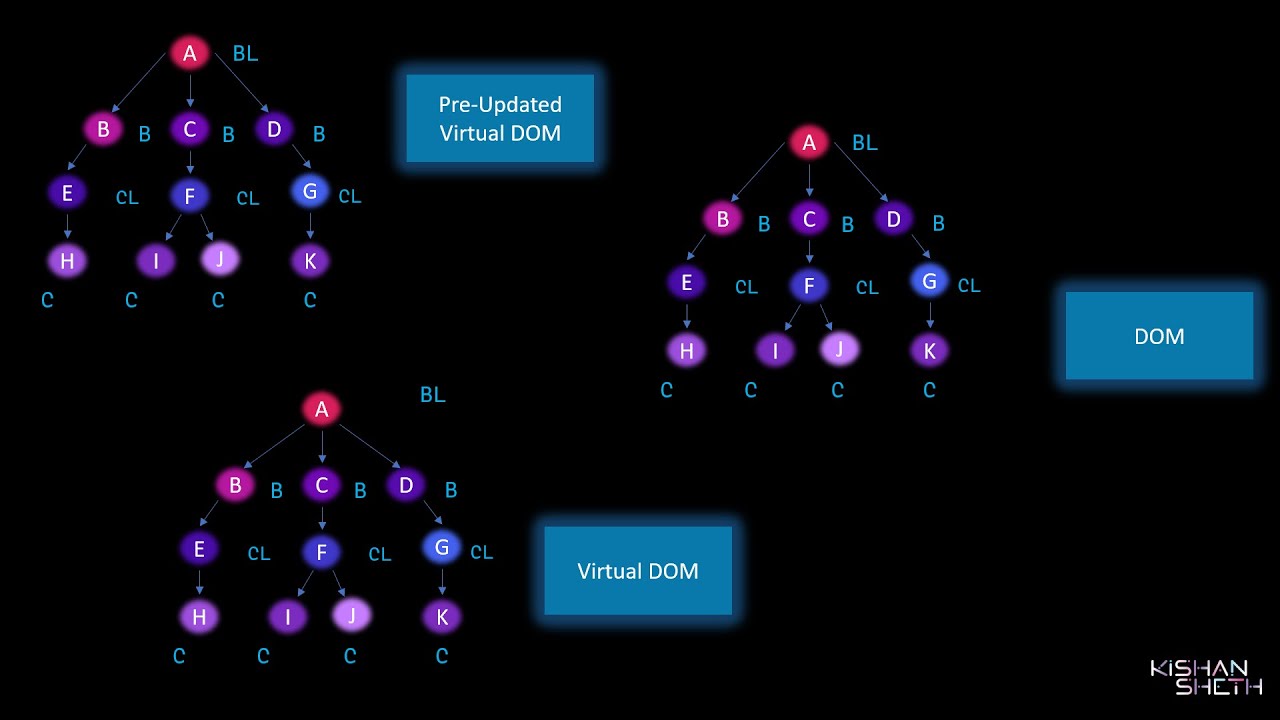
Сверка - это процесс, посредством которого React обновляет DOM. Когда состояние компонента изменяется, React должен вычислить, нужно ли обновлять DOM. Он делает это, создавая виртуальную модель DOM и сравнивая ее с текущей моделью DOM. В этом контексте виртуальная модель DOM будет содержать новое состояние компонента.
Ключевая идея React API — мыслить об апдейтах так, если бы они могли привести к полной отрисовке приложения. Это позволяет разработчику действовать декларативно, а не переживать о том насколько рациональным будет переход приложения из одного состояния в другое (от А до B, B до С, С до A и тд.).
Создание минимального количества операций для преобразования одного дерева в другое - сложная и хорошо изученная проблема. Современные алгоритмы имеют сложность порядка O (n3), где n - количество узлов в дереве.
Это означает, что для отображения 1000 узлов потребуется порядка одного миллиарда сравнений. Это слишком дорого для нашего случая использования. Для сравнения: современные процессоры выполняют примерно 3 миллиарда инструкций в секунду. Так что даже с самой производительной реализацией мы не сможем вычислить разницу менее чем за секунду.
Поскольку оптимальный алгоритм не поддается обработке, мы реализуем неоптимальный O (n) алгоритм с использованием эвристики, основанной на двух предположениях:
- Два компонента одного класса будут генерировать похожие деревья, а два компонента разных классов будут генерировать разные деревья.
- Можно предоставить уникальный ключ для элементов, который будет стабильным при разных рендерингах.
На практике эти предположения невероятно быстры почти для всех практических случаев использования.
Попарное различие
Чтобы провести различие между деревом, нам сначала нужно иметь возможность различать два узла. Рассматриваются три разных случая.
Различные типы узлов
Если тип узла отличается, React будет рассматривать их как два разных поддерева, выбросить первое и построить / вставить второе.
renderA: <div />
renderB: <span />
=> [removeNode <div />], [insertNode <span />]Та же логика используется для пользовательских компонентов. Если они не одного типа, React даже не попытается сопоставить то, что они отображают. Он просто удалит первый из DOM и вставит второй.
renderA: <Header />
renderB: <Content />
=> [removeNode <Header />], [insertNode <Content />]Наличие такого высокого уровня знаний является очень важным аспектом того, почему алгоритм сравнения React является быстрым и точным. Он обеспечивает хорошую эвристику, чтобы быстро обрезать большие части дерева и сосредоточиться на частях, которые могут быть похожими.
Очень маловероятно, что элемент <Header> будет генерировать DOM, который будет выглядеть так, как сгенерировал бы <Content>. Вместо того, чтобы тратить время на попытки сопоставить эти две структуры, React просто заново строит дерево с нуля.
Как следствие, если есть элемент <Header> в одной и той же позиции в двух последовательных отрисовках, вы ожидаете увидеть очень похожую структуру, и ее стоит изучить.
Узлы DOM
При сравнении двух узлов DOM мы смотрим на атрибуты обоих и можем решить, какой из них изменился за линейное время.
renderA: <div id="before" />
renderB: <div id="after" />
=> [replaceAttribute id "after"]Вместо того, чтобы рассматривать стиль как непрозрачную строку, вместо него используется объект «ключ-значение». Это позволяет нам обновлять только те свойства, которые изменились.
renderA: <div style={{color: 'red'}} />
renderB: <div style={{fontWeight: 'bold'}} />
=> [removeStyle color], [addStyle font-weight 'bold']После обновления атрибутов мы выполняем рекурсию для всех дочерних элементов.
Пользовательские компоненты
Мы решили, что эти два пользовательских компонента одинаковы. Поскольку компоненты сохраняют состояние, мы не можем просто использовать новый компонент и доводить его до конца. React берет все атрибуты из нового компонента и вызывает component[Will/Did]ReceiveProps() для предыдущего.
Предыдущий компонент теперь в рабочем состоянии. Вызывается его метод render (), и алгоритм сравнения перезапускается с новым результатом и предыдущим результатом.
Список различий
Проблемный случай
Для сравнения детей React использует очень наивный подход. Он просматривает оба списка потомков одновременно и генерирует мутацию всякий раз, когда есть разница.
Например, если вы добавите элемент в конце:
renderA: <div><span>first</span></div>
renderB: <div><span>first</span><span>second</span></div>
=> [insertNode <span>second</span>]Вставить элемент в начало проблематично. React увидит, что оба узла являются промежутками и, следовательно, находятся в режиме мутации.
renderA: <div><span>first</span></div>
renderB: <div><span>second</span><span>first</span></div>
=> [replaceAttribute textContent 'second'], [insertNode <span>first</span>]Существует множество алгоритмов, которые пытаются найти минимальный набор операций для преобразования списка элементов. Расстояние Левенштейна можно найти минимум, используя вставку, удаление и замену одного элемента в O (n2). Даже если бы мы использовали Левенштейна, это не обнаружит, когда узел переместился в другую позицию, и алгоритмы для этого имеют гораздо худшую сложность.
Ключи
Чтобы решить эту, казалось бы, неразрешимую проблему, был введен дополнительный атрибут. Вы можете предоставить каждому дочернему элементу ключ, который будет использоваться для сопоставления. Если вы укажете ключ, React теперь может находить вставку, удаление, замену и перемещение за O (n) с помощью хеш-таблицы.
renderA: <div><span key="first">first</span></div>
renderB: <div><span key="second">second</span><span key="first">first</span></div>
=> [insertNode <span>second</span>]На практике найти ключ не так уж и сложно. В большинстве случаев элемент, который вы собираетесь отображать, уже имеет уникальный идентификатор. Если это не так, вы можете добавить новое свойство ID в свою модель или хешировать некоторые части контента для генерации ключа. Помните, что ключ должен быть уникальным только среди своих братьев и сестер, а не глобально.
Компромиссы
Важно помнить, что алгоритм согласования - это деталь реализации.React мог повторно отображать все приложение при каждом действии;конечный результат будет таким же.Мы регулярно совершенствуем эвристику, чтобы ускорить распространенные варианты использования.
В текущей реализации вы можете выразить тот факт, что поддерево было перемещено между своими братьями и сестрами, но вы не можете сказать, что оно переместилось в другое место.Алгоритм повторно визуализирует это полное поддерево.
Поскольку мы полагаемся на две эвристики, если лежащие в основе них допущения не выполняются, производительность пострадает
- Алгоритм не будет пытаться сопоставить поддеревья разных классов компонентов. Если вы видите, что чередуете два класса компонентов с очень похожими выходными данными, вы можете сделать их одним и тем же классом. На практике мы не обнаружили в этом проблемы.
- Ключи должны быть стабильными, предсказуемыми и уникальными. Нестабильные ключи (например, созданные Math.random ()) вызовут ненужное повторное создание многих узлов, что может вызвать снижение производительности и потерю состояния дочерних компонентов.
Что же такое Fiber?
Мы будем обсуждать сердце архитектуры React Fiber. Fiber — это более низкоуровневая абстракция над приложением чем разработчики привыкли считать. Если вы считаете свои попытки понять ее безнадежными, не чувствуйте себе обескураженными (вы не одни). Продолжайте искать и это в конце-концов даст свои плоды.
И так!
Мы достигли той главной цели архитектуры Fiber — позволить React воспользоваться планированием. Конкретно, нам нужно иметь возможность:
- остановить работу и вернуться к ней позже.
- приоритизировать разные типы работы.
- переиспользовать работу проделанную ранее.
- отменить работу, если она больше не нужна.